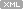
decode(a, b, c, d)
a가 b 이면 c이고 아니면 d이다.
예제 쿼리로 보면.....
select decode(sum(c1)+sum(c2),0,null,sum(c1)+sum(c2)) from test
sum(c1)+sum(c2) 요놈이 0 이면
null 을 뽑고 아니면 sum(c1)+sum(c2) 요걸 뽑고....뭐...단순 예제다보니....-0-;;;
a가 b 이면 c이고 아니면 d이다.
예제 쿼리로 보면.....
select decode(sum(c1)+sum(c2),0,null,sum(c1)+sum(c2)) from test
sum(c1)+sum(c2) 요놈이 0 이면
null 을 뽑고 아니면 sum(c1)+sum(c2) 요걸 뽑고....뭐...단순 예제다보니....-0-;;;

